
Tesla and the Unreasonable Effectiveness of Data

Why does the size of Tesla’s training fleet matter? It’s well over 1 million cars, with the fleets of all competitors worldwide amounting to a combined size of well under 10,000. But is data really that important? Can you really get much more with 1 million+ cars than with 100 or 1,000? Yes. (Note: I am long shares of TSLA.)
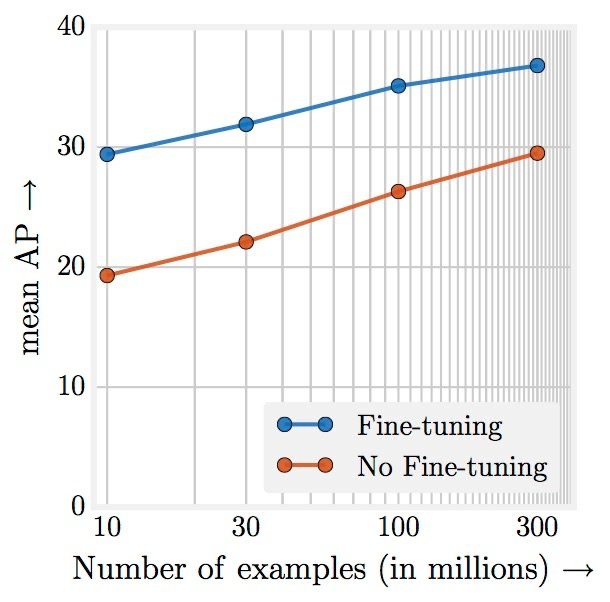
A paper and accompanying blog post by Google AI called “Revisiting the Unreasonable Effectiveness of Data” emphasizes that neural networks continue to improve logarithmically as noisily labelled training datasets grow exponentially, up to at least the scale of 300 million examples, as long as the neural network has enough capacity (in terms of size/depth) to absorb the training signal.
From the blog post:
Our first observation is that large-scale data helps in representation learning which in-turn improves the performance on each vision task we study. Our findings suggest that a collective effort to build a large-scale dataset for visual pretraining is important. It also suggests a bright future for unsupervised and semi-supervised representation learning approaches. It seems the scale of data continues to overpower noise in the label space.
Another important excerpt:
It is important to highlight that the training regime, learning schedules and parameters we used are based on our understanding of training ConvNets with 1M images from ImageNet. Since we do not search for the optimal set of hyper-parameters in this work (which would have required considerable computational effort), it is highly likely that these results are not the best ones you can obtain when using this scale of data. Therefore, we consider the quantitative performance reported to be an underestimate of the actual impact of data for all reported image volumes.
Facebook AI later took this even further, using a dataset of 1 billion images.
In certain applications of deep learning – and my contention is that autonomous driving is one of them – the ceiling on neural network performance is imposed by the quantity of available data.
What about labelling? As many papers have shown, various techniques such as weak/noisy labelling, self-supervised learning, and automatic curation through techniques like active learning can leverage very large quantities of data for better neural network performance with an increase in hand annotation.
An example of Tesla using self-supervised learning:
In the autonomous driving subdomain of planning, imitation learning and reinforcement learning can – at least in theory and somewhat in practice already – leverage real world data to train neural network without any human annotators in the loop (besides the drivers).
As a general principle of deep learning, it’s not controversial to say performance scales with data and neural network size, with no known limit as of now. It has become less controversial over the last few years that techniques like imitation learning, reinforcement learning, and self-supervised learning are highly promising, and virtually all autonomous vehicle companies as far as I’m aware have started to at least experiment with one or more of them, if not deploy them to their fleet.
If we apply this general principle in the specific case of Tesla, the inference is clear: Tesla is working under a much higher ceiling than everyone else. Everyone else combined, in fact.
It is my strong belief that this advantage will become plain to see over the next few years, perhaps starting as early as this year. I wouldn’t be surprised if, in a few years from now, people said it was always obvious this would happen.
Common objections
What about lidar?
Before you bring up lidar, watch this video and then come back with an argument about why Levandowski is wrong:
Secondly, if lidar really is the secret sauce… Neural networks trained via Tesla’s production fleet can be deployed in any cars. What’s to stop Tesla from using lidar like everyone else, at the same scale as everyone else, with (non-lidar-related) neural networks that far surpass what everyone else has?
The proof is in the pudding!
Indeed, but this amounts to an argument against making predictions in general. Once everything has already happened, it’s too late to predict what will happen. Once the results are in, it’s too late to place a bet. Predicting the future inherently involves speculating about an uncertain unfolding of events.
Waymo already cracked it!
Really? Then why does Waymo not seem to think so? If they really believed they had solved autonomous driving, they would be focused on expanding, on scaling up. They don’t seem to be. This article provides some food for thought.
Another company has more data than Tesla
No, they don’t. Not the kind of data we’re talking about. For example, Uber has a massive amount of GPS data from cars, but that is useless for training an autonomous driving system. Other companies’ data collection operations are just not comparable at all. Mobileye, for instance, doesn’t have the ability to upload sensor data or push new firmware to the car.